import scrapy
from imgsPro.items import ImgsproItem
classImgSpider(scrapy.Spider):
name ='img'# allowed_domains = ['www.xxx.com']
start_urls =['https://sc.chinaz.com/tupian/']defparse(self, response):
div_list = response.xpath('//div[@id="container"]/div')for div in div_list:#注意伪属性
img_url ='https:'+ div.xpath('./div/a/img/@src2').extract()[0]
item = ImgsproItem(img_url=img_url)yield item
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
items.py
# Define here the models for your scraped items## See documentation in:# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapy
classImgsproItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()
img_url = scrapy.Field()#pass
1
2
3
4
5
6
7
8
9
10
11
12
13
14
1
2
3
4
5
6
7
8
9
10
11
12
13
14
pipeline.py
# Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interfacefrom itemadapter import ItemAdapter
# class ImgsproPipeline:# def process_item(self, item, spider):# return itemfrom scrapy.pipelines.images import ImagesPipeline
import scrapy
classimgsPipeLine(ImagesPipeline):#根据图片地址进行数据请求defget_media_requests(self,item,info):yield scrapy.Request(item['img_url'])#指定图片存储类型deffile_path(self,request,response=None,info=None):
imgName = request.url.split('/')[-1]return imgName
# def item_completed(self,results,item,info):# return item #返回给下一个即将执行的管道类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
setting.py
BOT_NAME ='imgsPro'
SPIDER_MODULES =['imgsPro.spiders']
NEWSPIDER_MODULE ='imgsPro.spiders'
LOG_LEVEL ='ERROR'# Crawl responsibly by identifying yourself (and your website) on the user-agent#USER_AGENT = 'imgsPro (+http://www.yourdomain.com)'
USER_AGENT ='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'# Obey robots.txt rules
ROBOTSTXT_OBEY =False# Configure item pipelines# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES ={'imgsPro.pipelines.imgsPipeLine':300,}#指定图片存储路径
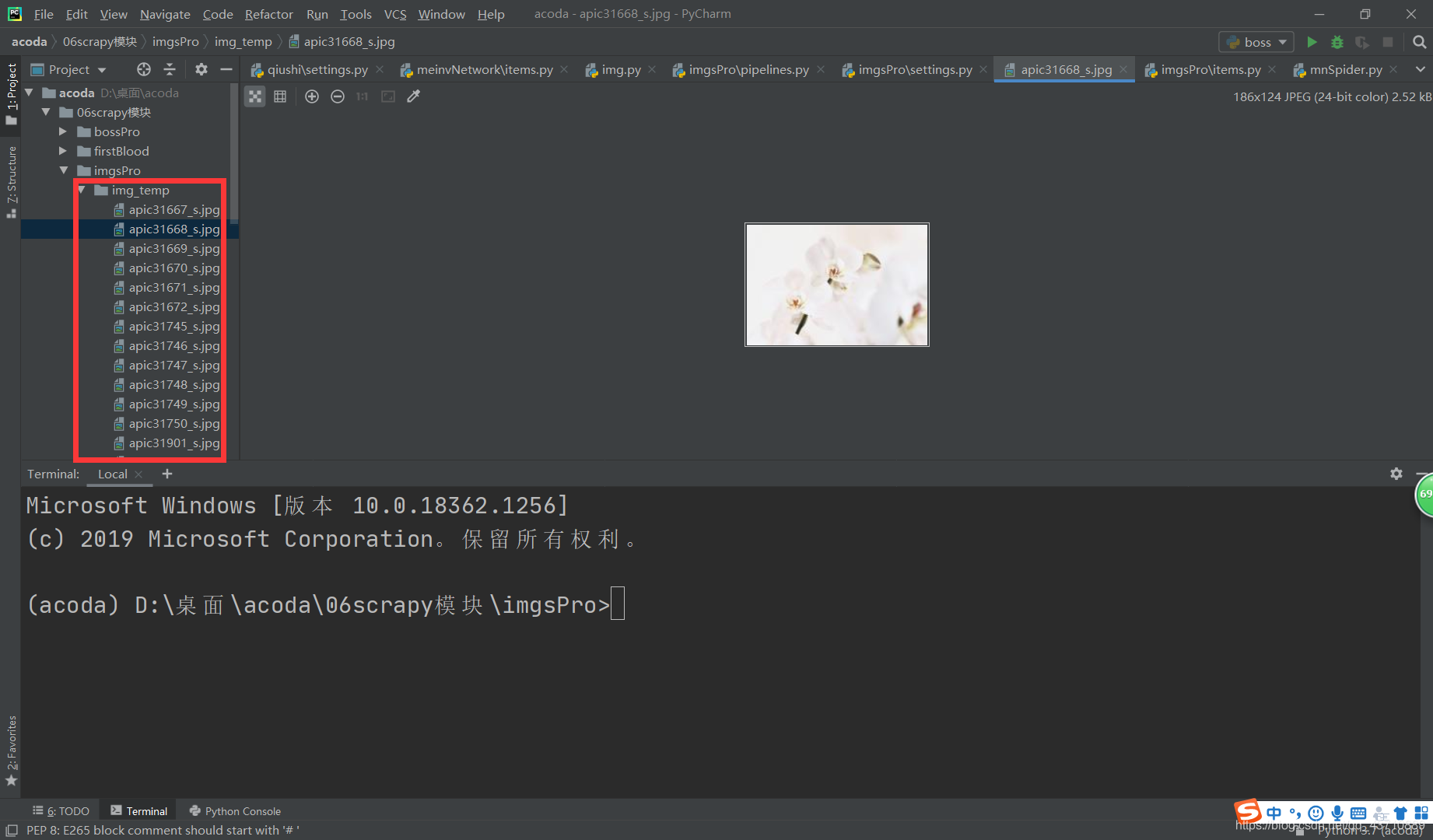
IMAGES_STORE ='./img_temp'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
效果图
中间件的使用
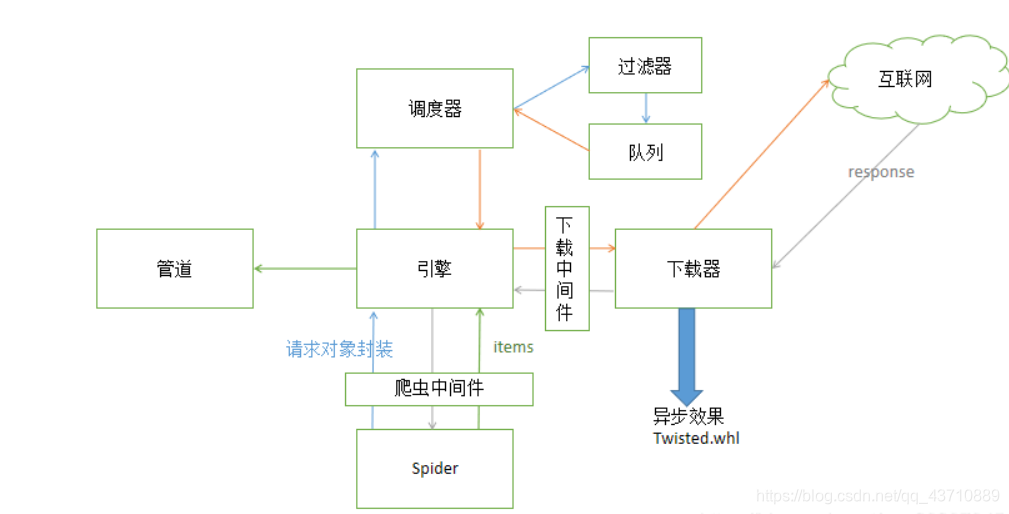
下载中间件
位置:引擎和下载器之间
作用:批量拦截到整个工程中的所有请求和响应
拦截请求:
UA伪装
代理IP
拦截响应:篡改响应数据,响应对象。
中间件案例:网易新闻
https://news.163.com/
需求:爬取网易新闻中的新闻数据(标题和内容)
1.通过网易新闻的首页解析出五大板块对应的详情页的url (没有动态加载)
2.每一个板块对应的新闻标题都是动态加载出来的(动态加载)
3.通过解析出每一条新闻详情页的url获取详情页的页面源码,解析出新闻内容
目录层级
wangyi.py
import scrapy
from selenium import webdriver
from wangyiPro.items import WangyiproItem
classWangyiSpider(scrapy.Spider):
name ='wangyi'# allowed_domains = ['www.xxx.com']
start_urls =['https://news.163.com/']
model_urls =[]def__init__(self):
self.bro = webdriver.Chrome(executable_path=r"E:\google\Chrome\Application\chromedriver.exe")defparse(self, response):
li_list = response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li')
alist =[3,4,6,7,8]for i in alist:
model_url = li_list[i].xpath('./a/@href').extract_first()
self.model_urls.append(model_url)for url in self.model_urls:yield scrapy.Request(url,callback=self.model_parse)defmodel_parse(self,response):
div_list = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div[1]/div/ul/li/div/div')for div in div_list:
title = div.xpath('./div/div[1]/h3/a/text()').extract_first()
new_detail_url = div.xpath('./div/div[1]/h3/a/@href').extract_first()if new_detail_url ==None:continue
item = WangyiproItem()
item['title']= title
yield scrapy.Request(url=new_detail_url,callback=self.parse_detail,meta={'item':item})defparse_detail(self,response):
content = response.xpath('//*[@id="content"]/div[2]//text()').extract()
content =''.join(content)
item = response.meta['item']
item['content']= content
yield item
defclosed(self,spider):
self.bro.quit()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
items.py
# Define here the models for your scraped items## See documentation in:# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapy
classWangyiproItem(scrapy.Item):# define the fields for your item here like:
title = scrapy.Field()
content = scrapy.Field()
1
2
3
4
5
6
7
8
9
10
11
12
13
1
2
3
4
5
6
7
8
9
10
11
12
13
middlewares.py
# Define here the models for your spider middleware## See documentation in:# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlfrom scrapy import signals
# useful for handling different item types with a single interfacefrom itemadapter import is_item, ItemAdapter
from scrapy.http import HtmlResponse
from time import sleep
classWangyiproDownloaderMiddleware:# Not all methods need to be defined. If a method is not defined,# scrapy acts as if the downloader middleware does not modify the# passed objects.defprocess_request(self, request, spider):# Called for each request that goes through the downloader# middleware.# Must either:# - return None: continue processing this request# - or return a Response object# - or return a Request object# - or raise IgnoreRequest: process_exception() methods of# installed downloader middleware will be calledreturnNonedefprocess_response(self, request, response, spider):
bro = spider.bro
if request.url in spider.model_urls:
bro.get(request.url)
sleep(2)
page_text = bro.page_source
new_response = HtmlResponse(url=request.url,body=page_text,encoding='utf-8',request=request)return new_response
else:return response
defprocess_exception(self, request, exception, spider):# Called when a download handler or a process_request()# (from other downloader middleware) raises an exception.# Must either:# - return None: continue processing this exception# - return a Response object: stops process_exception() chain# - return a Request object: stops process_exception() chainpass
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
pipelines.py
# Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interfacefrom itemadapter import ItemAdapter
classWangyiproPipeline:
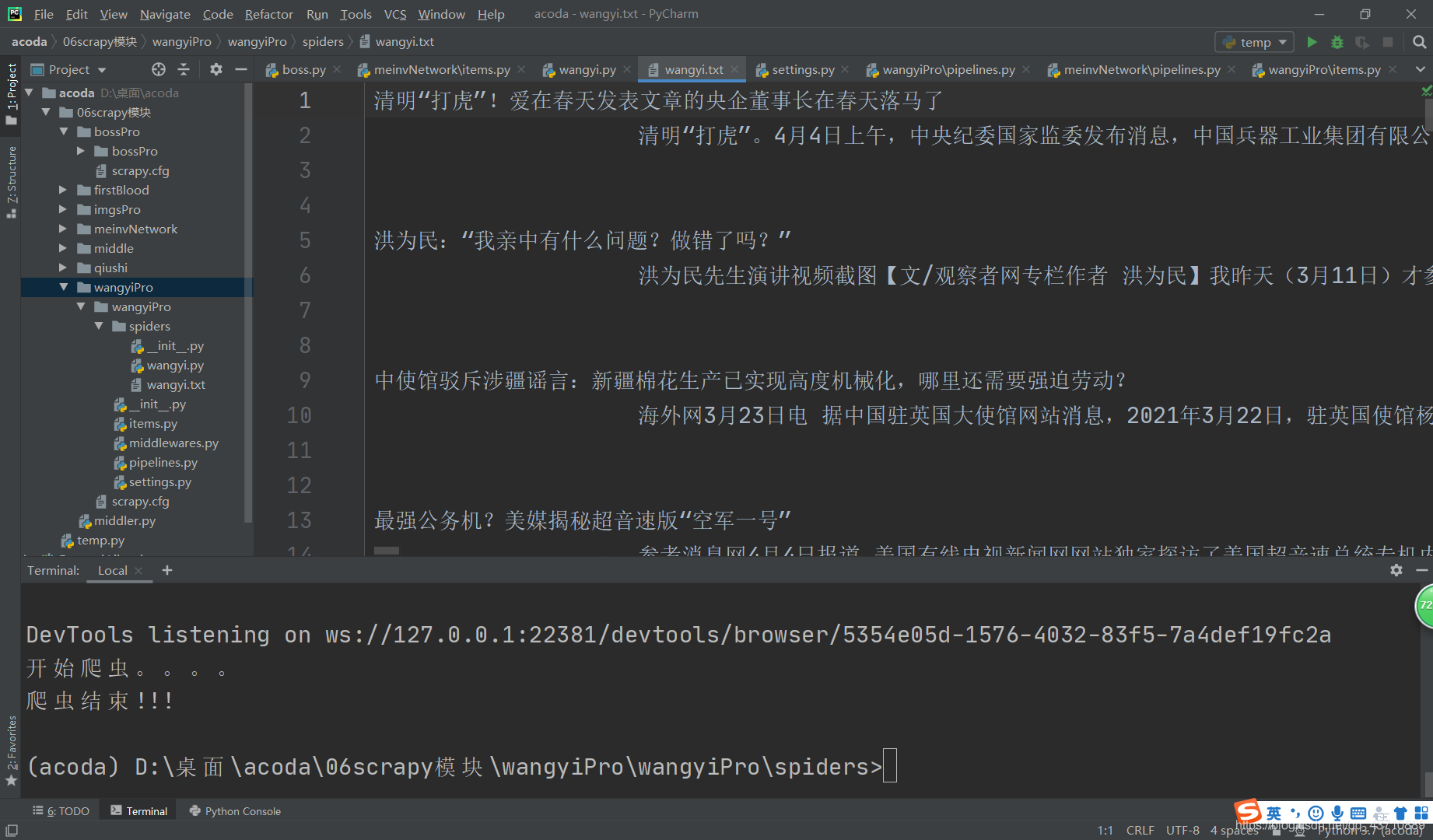
fp =None# 重写父类的一个方法:该方法只在爬虫开始的时候被调用一次defopen_spider(self, spider):print('开始爬虫。。。。')
self.fp =open('./wangyi.txt','w', encoding='utf-8')defclose_spider(self, spider):print('爬虫结束!!!')
self.fp.close()defprocess_item(self, item, spider):
title = item['title']
content = item['content']
self.fp.write(title+content +'\n')return item
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
setting.py
BOT_NAME ='wangyiPro'
SPIDER_MODULES =['wangyiPro.spiders']
NEWSPIDER_MODULE ='wangyiPro.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT ='Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11'
LOG_LEVEL ='ERROR'# Obey robots.txt rules
ROBOTSTXT_OBEY =False# Enable or disable downloader middlewares# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES ={'wangyiPro.middlewares.WangyiproDownloaderMiddleware':543,}# Enable or disable extensions# See https://docs.scrapy.org/en/latest/topics/extensions.html#EXTENSIONS = {# 'scrapy.extensions.telnet.TelnetConsole': None,#}# Configure item pipelines# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES ={'wangyiPro.pipelines.WangyiproPipeline':300,}