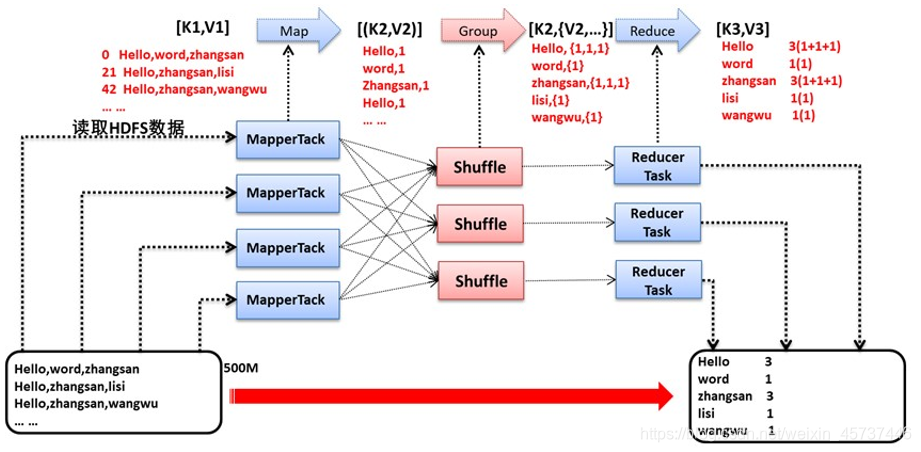
Map的输出 是key,value的 list
Reduce的输入是key。value的list
MapReduce核心思想
分而治之,先分后和(只有一个模型)
Map负责数据拆分 map: [k1,v1] → [(k2,v2)]
Reduce负责数据合并 reduce: [k2, {v2,…}] → [k3, v3]
Mapreduce的输入是一个目录,那么会将目录内的所有文件进行读取计算,
若是一个文件,那么只计算该文件。
Mapreduce的输出路径绝对不能已存在
Mapreduce Maptask不能人为设置
Reducetask可以人为设置,task越多速度越快
job.setNumReduceTasks(5);
将代码打包(jar)上传到集群运行需要在driver中添加以下代码
job.setJarByClass(WordCountDriver.class);
MapReduce执行流程
第一步:InputFormat
InputFormat 在HDFS文件系统中读取要进行计算的数据
输出给Split
第二步:Split
Split 将数据进行逻辑切分,切分成多个任务。
输出给RR
第三步:RR
RR 将切分后的数据转换成key value进行输出
key : 每一行行首字母的偏移量
value: 每一行数据
输出给Map
第四步:Map
接收一条一条的数据(有多少行数据Map运行多少次,输出的次数根据实际业务需求而定)
根域业务需求编写代码
Map的输出是 key value的 list
输出给Shuffle(partition)
---------------------------------------Map-------------------------------------------------------
第五步: partition
partition: 按照一定的规则对 **key value的 list进行分区
输出给Shuffle(sort)
第六步:Sort
Sort :对每个分区内的数据进行排序。
输出给Shuffle(Combiner)
第七步:Combiner
Combiner: 在Map端进行局部聚合(汇总)
目的是为了减少网络带宽的开销
输出给Shuffle(Group)
第八步:Group
Group: 将相同key的key提取出来作为唯一的key
将相同key对应的value提取出来组装成一个value 的List
输出给Shuffle(reduce)
------------------------------------Shuffle--------------------------------------------
第九步:reduce
reduce: 根据业务需求对传入的数据进行汇总计算。
输出给Shuffle(outputFormat)
第十步:outputFormat
outputFormat:将最终的额结果写入HDFS
------------------------------------reduce--------------------------------------------

MapReduce程序运行模式
本地运行模式
(1)mapreduce程序是被提交给LocalJobRunner在本地以单进程的形式运行
(2)而处理的数据及输出结果可以在本地文件系统,也可以在hdfs上
(3)怎样实现本地运行?写一个程序,不要带集群的配置文件
本质是程序的conf中是否有mapreduce.framework.name=local以及yarn.resourcemanager.hostname=local参数
(4)本地模式非常便于进行业务逻辑的debug,只要在eclipse中打断点即可
本地模式运行代码设置
configuration.set("mapreduce.framework.name","local");
configuration.set("yarn.resourcemanager.hostname","local");
TextInputFormat.addInputPath(job,new Path("file:///F:\\离线阶段课程资料\\3、大数据离线第三天 \\wordcount\\input"));
TextOutputFormat.setOutputPath(job,new Path("file:///F:\\离线阶段课程资料\\3、大数据离线第三天\\wordcount\\output"));
集群运行模式
(1)将mapreduce程序提交给yarn集群,分发到很多的节点上并发执行
(2)处理的数据和输出结果应该位于hdfs文件系统
(3)提交集群的实现步骤:
将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启动
hadoop jar hadoop-1.0-SNAPSHOT.jar cn.itcast.hdfs.demo1.JobMain











