看啥推荐读物

专栏名称: AI前线
| InfoQ十年沉淀,为千万技术人打造的专属AI公众号。追踪技术新趋势,跟踪头部科技企业发展和传统产业技术升级落地案例。囊括网站和近万人的机器学习知识交流社群。 |
今天看啥
微信公众号rss订阅, 微信rss, 稳定的RSS源
目录
相关文章推荐

|
爱可可-爱生活 · 【posteriors:基于 ...· 昨天 |
|
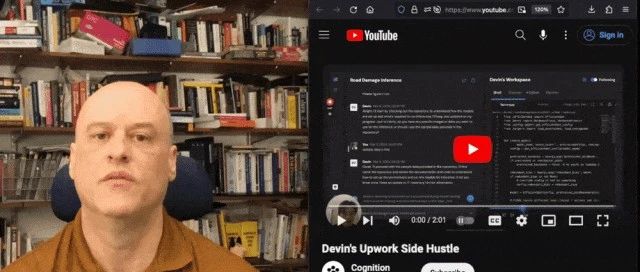
机器学习研究组订阅 · 世界首个AI程序员Devin视频竟造假?博主 ...· 4 天前 |

|
新智元 · 世界首个AI程序员Devin视频竟造假?博主 ...· 4 天前 |

|
宝玉xp · //@演员邵逸凡:转发微博-20240414 ...· 4 天前 |

推荐文章
|
|
宝玉xp · //@演员邵逸凡:转发微博-20240414073749 4 天前 |

|
扑克投资家 · 让人眼红的圭亚那海上世纪石油大发现 4 月前 |


|
亿翰智库 · 环沪30强 | 2019年1季度环沪楼盘销售业绩榜 5 年前 |

