def createTopics(timeout:Int,
validateOnly:Boolean,
toCreate:Map[String,CreatableTopic],
includeConfigsAndMetatadata:Map[String,CreatableTopicResult],
responseCallback:Map[String,ApiError]=>Unit):Unit={// 1. map over topics creating assignment and calling zookeeper
val brokers = metadataCache.getAliveBrokers.map { b =>kafka.admin.BrokerMetadata(b.id, b.rack)}
val metadata = toCreate.values.map(topic =>try{
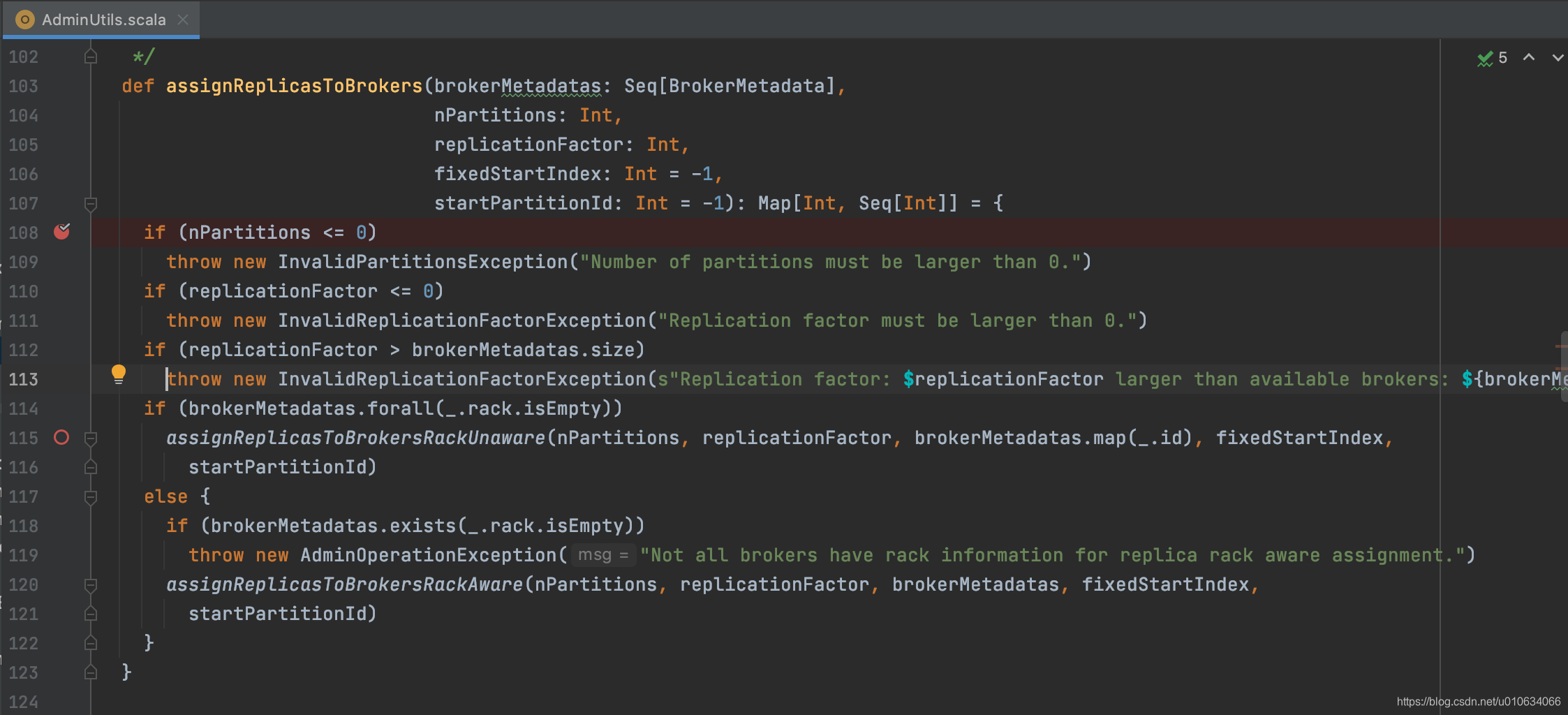
val assignments =if(topic.assignments().isEmpty){AdminUtils.assignReplicasToBrokers(
brokers, resolvedNumPartitions, resolvedReplicationFactor)}else{
val assignments =newmutable.HashMap[Int,Seq[Int]]// Note: we don't check that replicaAssignment contains unknown brokers - unlike in add-partitions case,// this follows the existing logic in TopicCommand
topic.assignments.asScala.foreach {case assignment =>assignments(assignment.partitionIndex())=
assignment.brokerIds().asScala.map(a => a:Int)}
assignments
}trace(s"Assignments for topic $topic are $assignments ")}
private def assignReplicasToBrokersRackAware(nPartitions:Int,
replicationFactor:Int,
brokerMetadatas:Seq[BrokerMetadata],
fixedStartIndex:Int,
startPartitionId:Int):Map[Int,Seq[Int]]={
val brokerRackMap = brokerMetadatas.collect {caseBrokerMetadata(id,Some(rack))=>
id -> rack
}.toMap
val numRacks = brokerRackMap.values.toSet.size
val arrangedBrokerList =getRackAlternatedBrokerList(brokerRackMap)
val numBrokers = arrangedBrokerList.size
val ret =mutable.Map[Int,Seq[Int]]()
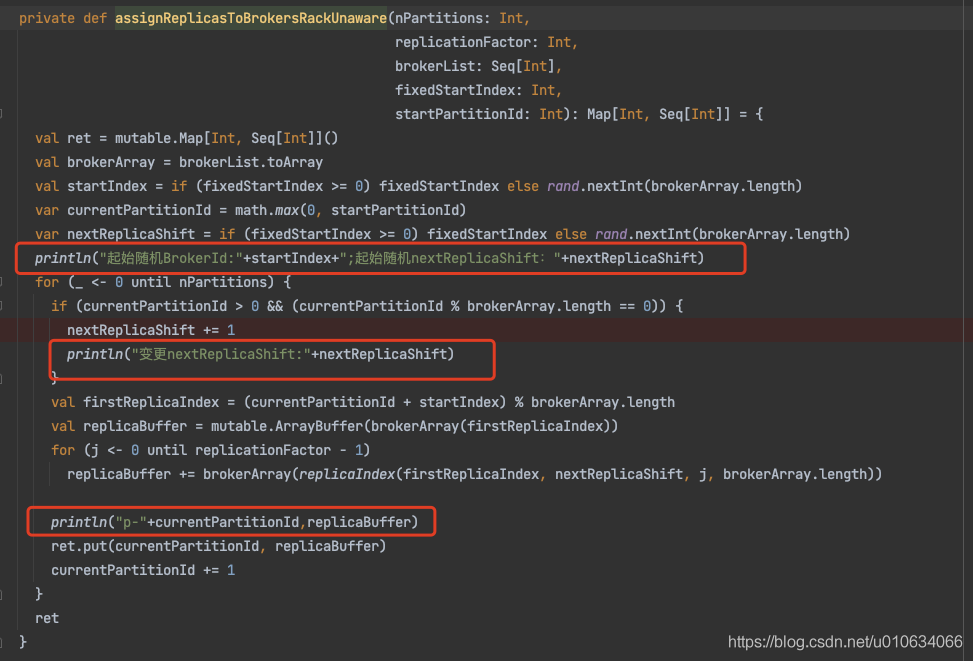
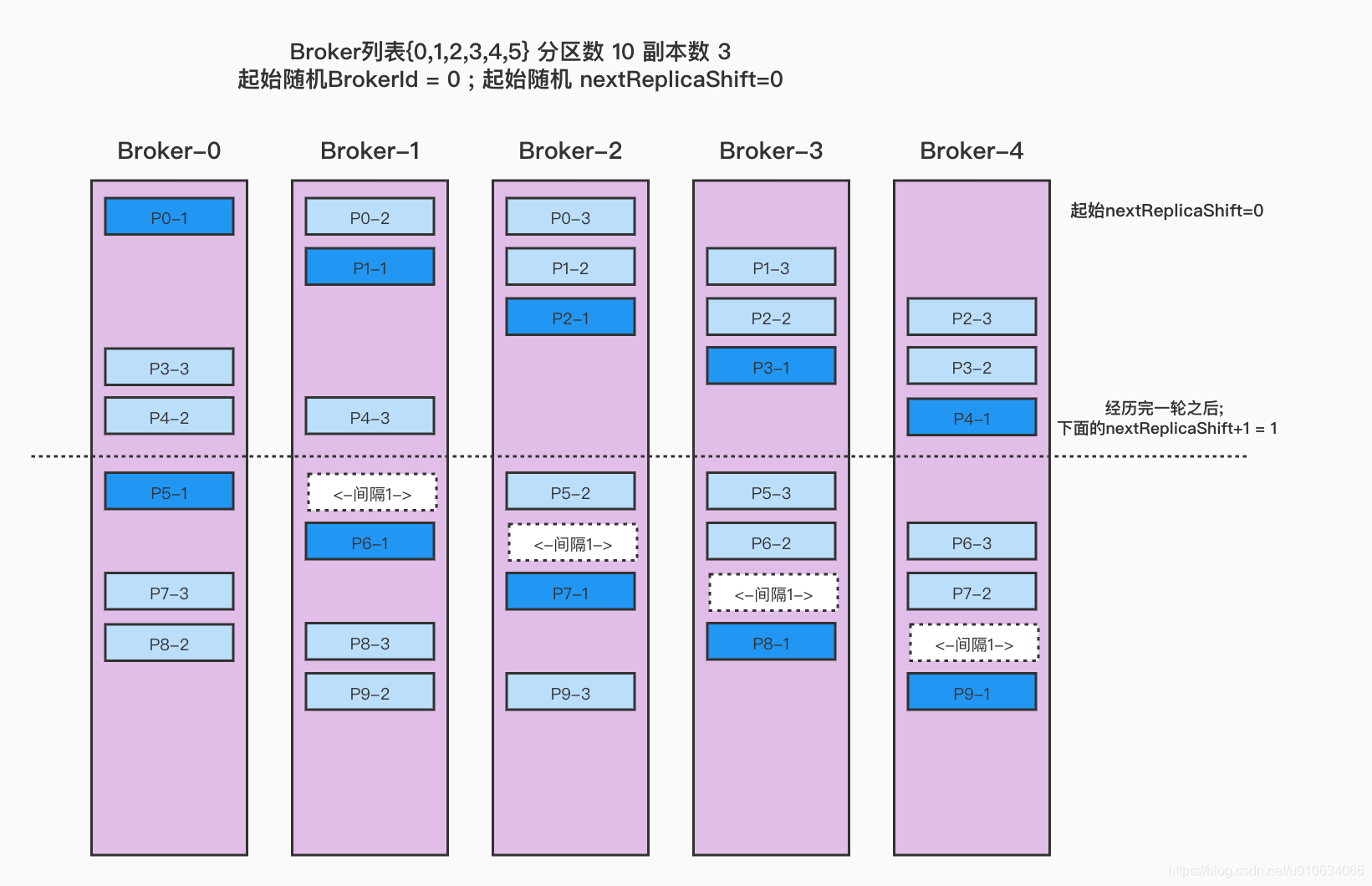
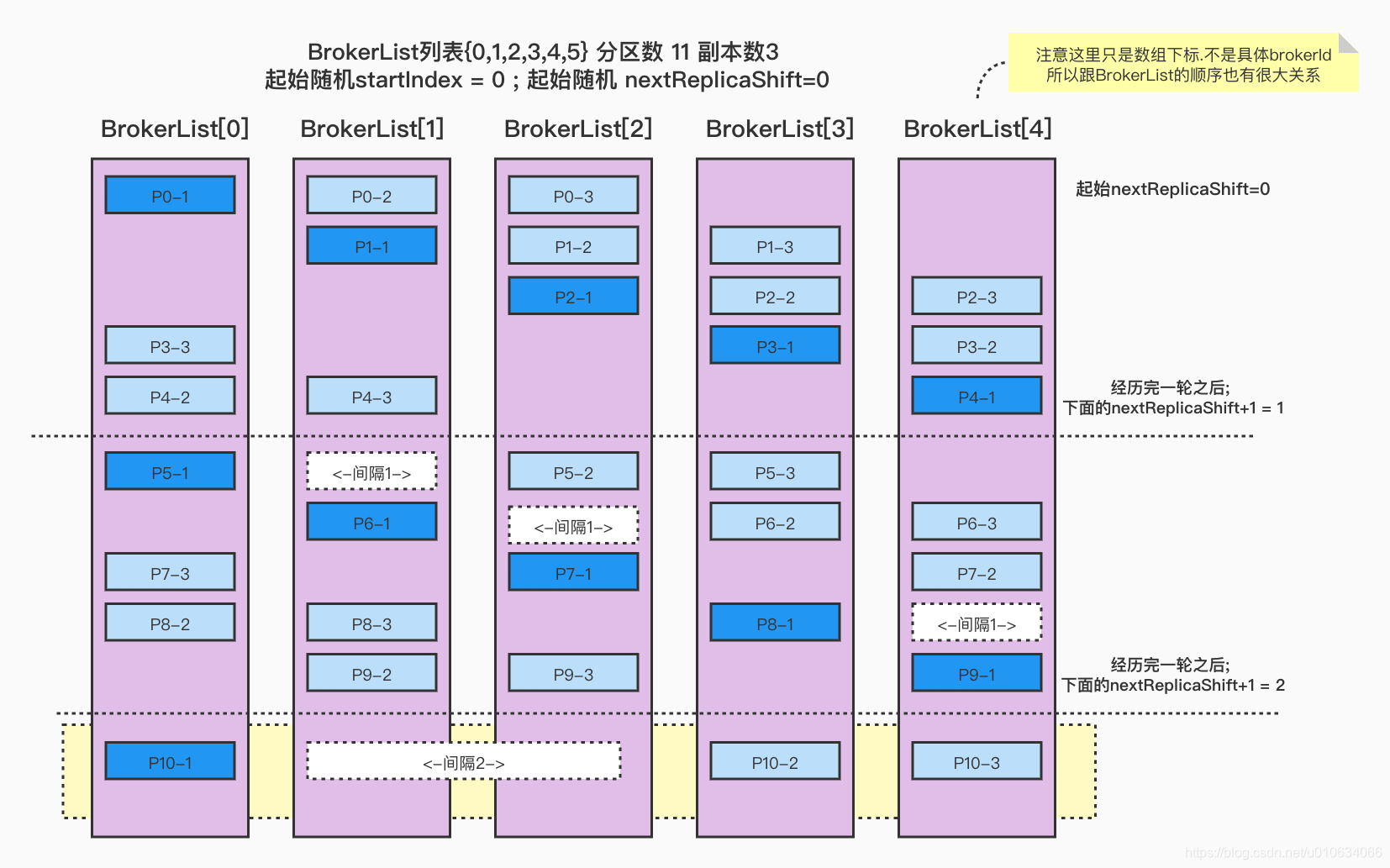
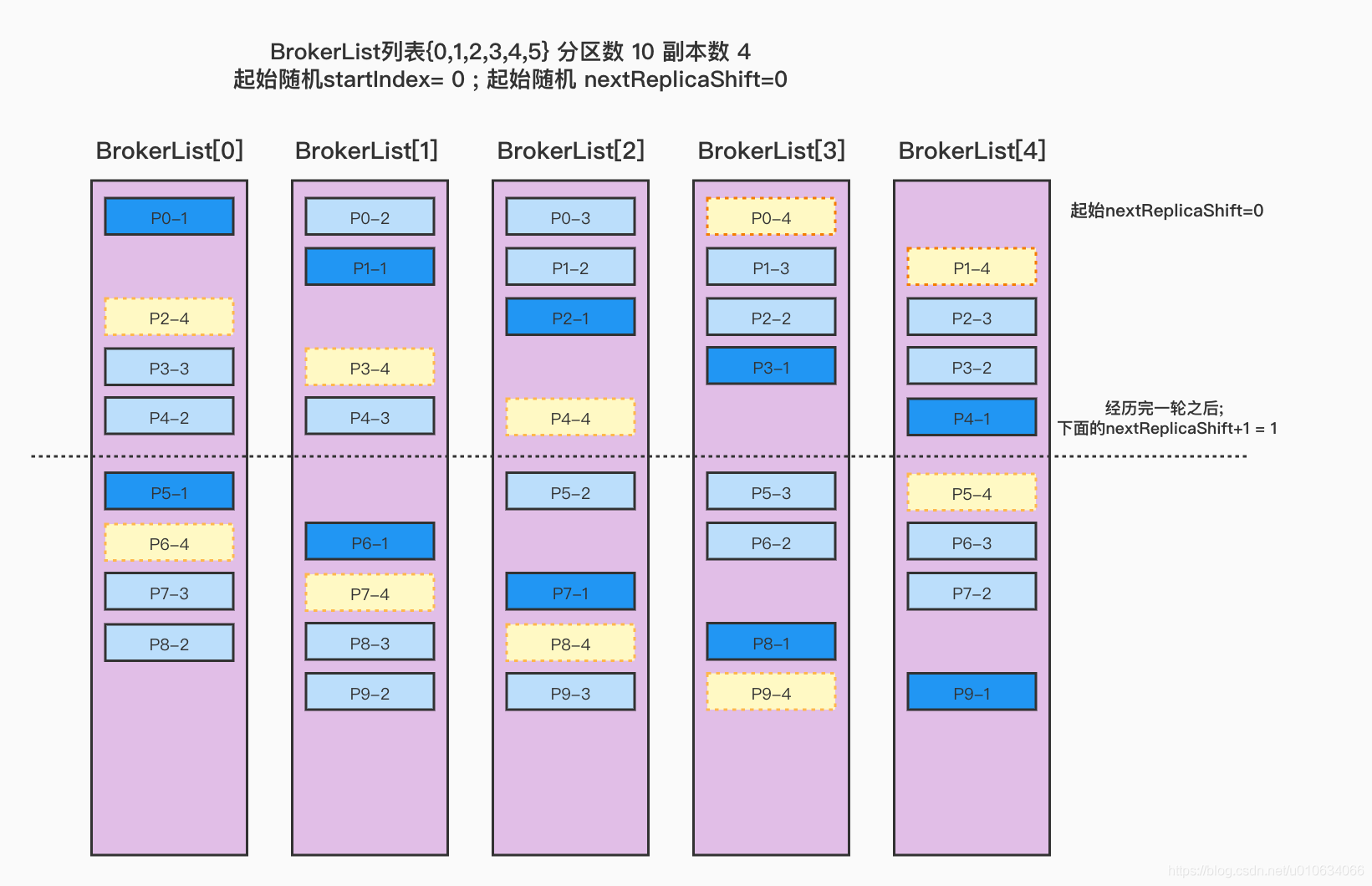
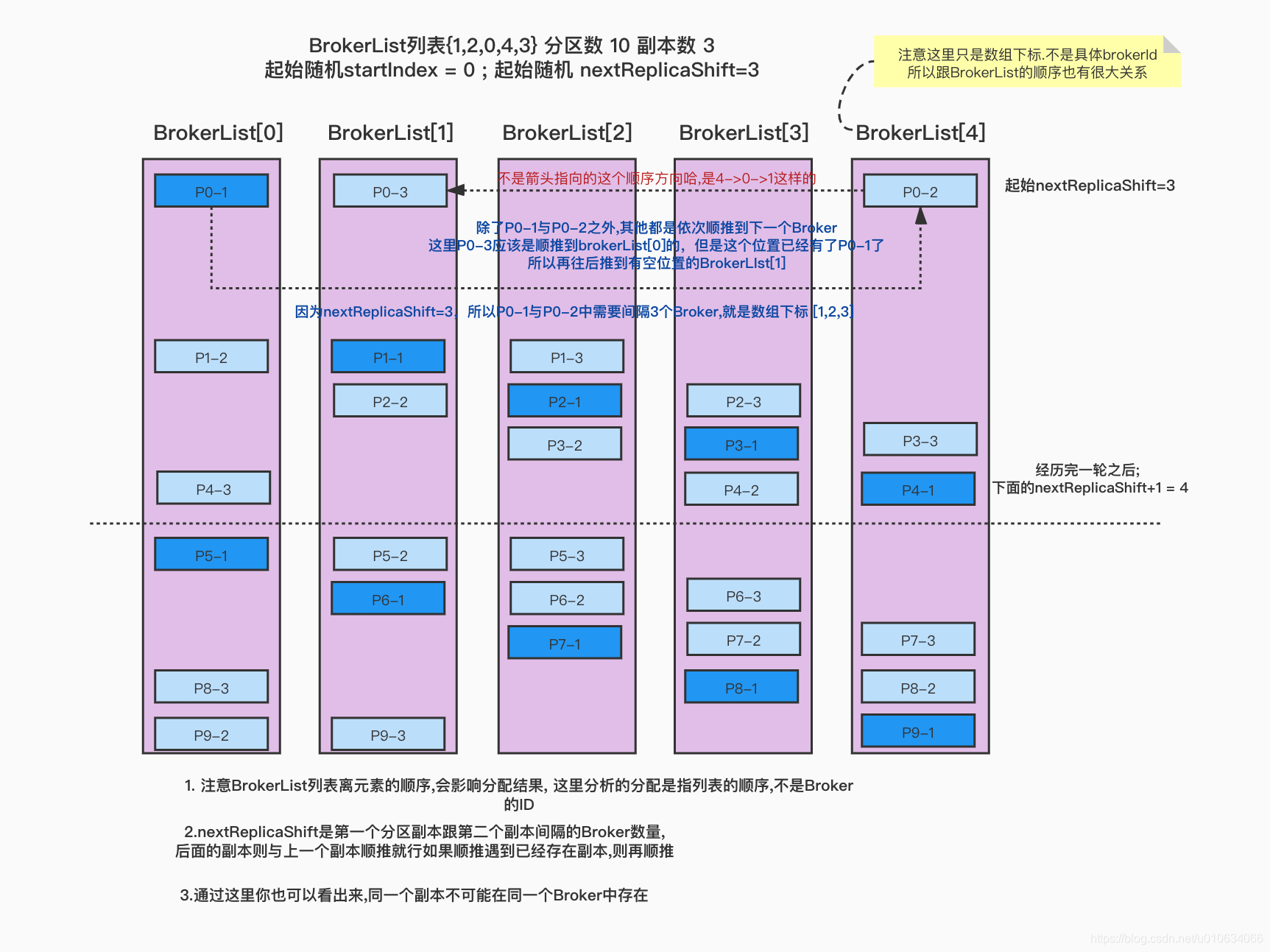
val startIndex =if(fixedStartIndex >=0) fixedStartIndex else rand.nextInt(arrangedBrokerList.size)var currentPartitionId = math.max(0, startPartitionId)var nextReplicaShift =if(fixedStartIndex >=0) fixedStartIndex else rand.nextInt(arrangedBrokerList.size)for(_ <-0 until nPartitions){if(currentPartitionId >0&&(currentPartitionId % arrangedBrokerList.size ==0))
nextReplicaShift +=1
val firstReplicaIndex =(currentPartitionId + startIndex)% arrangedBrokerList.size
val leader =arrangedBrokerList(firstReplicaIndex)
val replicaBuffer =mutable.ArrayBuffer(leader)
val racksWithReplicas =mutable.Set(brokerRackMap(leader))
val brokersWithReplicas =mutable.Set(leader)var k =0for(_ <-0 until replicationFactor -1){var done =falsewhile(!done){
val broker =arrangedBrokerList(replicaIndex(firstReplicaIndex, nextReplicaShift * numRacks, k, arrangedBrokerList.size))
val rack =brokerRackMap(broker)// Skip this broker if// 1. there is already a broker in the same rack that has assigned a replica AND there is one or more racks// that do not have any replica, or// 2. the broker has already assigned a replica AND there is one or more brokers that do not have replica assignedif((!racksWithReplicas.contains(rack)|| racksWithReplicas.size == numRacks)&&(!brokersWithReplicas.contains(broker)|| brokersWithReplicas.size == numBrokers)){
replicaBuffer += broker
racksWithReplicas += rack
brokersWithReplicas += broker
done =true}
k +=1}}
ret.put(currentPartitionId, replicaBuffer)
currentPartitionId +=1}
ret
}