看啥推荐读物

专栏名称: 机器之心
| 专业的人工智能媒体和产业服务平台 |
今天看啥
微信公众号rss订阅, 微信rss, 稳定的RSS源
目录
相关文章推荐
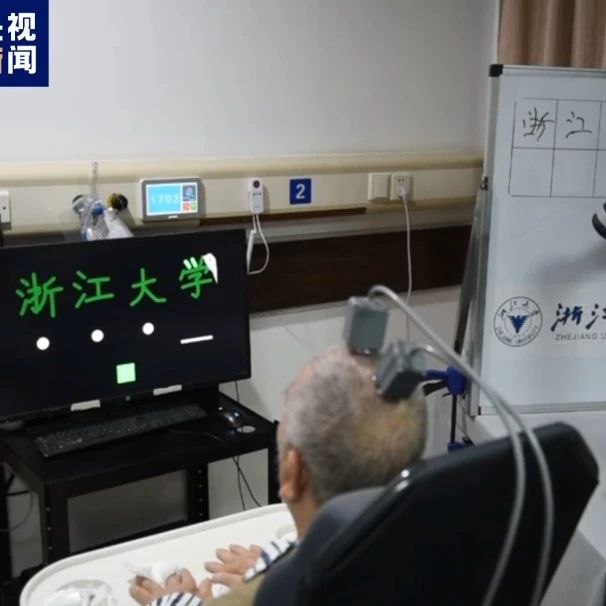
|
人工智能那点事 · 用意念写字?这所大学做了一件大事· 2 天前 |

|
爱可可-爱生活 · 【SAMMO:用于提示工程和优化的库,支持结 ...· 4 天前 |
|
|
爱可可-爱生活 · 【推理AI用数据大列表】’awesome-r ...· 5 天前 |

|
爱可可-爱生活 · [AS] A Large-Scale ...· 5 天前 |

推荐文章
|
|
人工智能那点事 · 用意念写字?这所大学做了一件大事 2 天前 |

|
办公室经验 · 莫让基层干部被“指尖上的形式主义”压垮 6 天前 |

|
FM93交通之声 · 首次!排海后检出来了! 7 月前 |


|
能源学人 · 合肥学院杨续来教授:虚焊对磷酸铁锂电池组性能的影响 1 年前 |

|
古籍 · 赵冬梅《大宋之变》:解剖一个朝代的兴盛与危辱 3 年前 |