看啥推荐读物

专栏名称: 数据派THU
| 本订阅号是“THU数据派”的姊妹账号,致力于传播大数据价值、培养数据思维。 |
今天看啥
微信公众号rss订阅, 微信rss, 稳定的RSS源
目录
相关文章推荐

|
大数据文摘 · 李飞飞团队发布《2024年人工智能指数报告》 ...· 2 天前 |

|
CDA数据分析师 · 【干货】数据仓库与业务数据库:企业数据管理的 ...· 4 天前 |

|
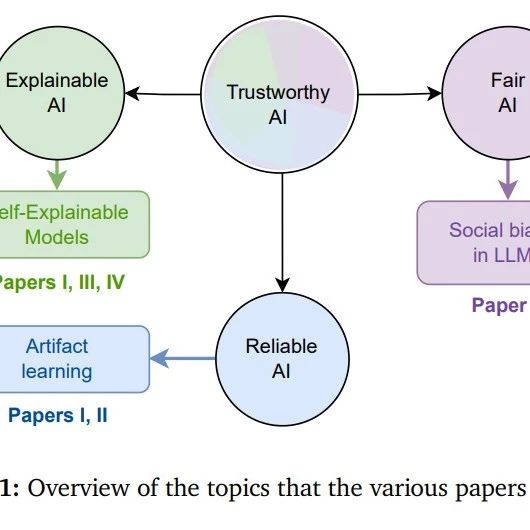
数据派THU · 【博士论文】可解释、可信赖和可靠的人工智能· 4 天前 |