看啥推荐读物

专栏名称: 生信媛
| 生信媛,从1人分享,到8人同行。坚持分享生信入门方法与课程,持续记录生信相关的分析pipeline, python和R在生物信息学中的利用。内容涵盖服务器使用、基因组转录组分析以及群体遗传。 |
今天看啥
微信公众号rss订阅, 微信rss, 稳定的RSS源
目录
相关文章推荐

|
生物制品圈 · qPCR突破传统检测局限,一技通用,细胞基因 ...· 2 天前 |

|
BioArt · Cell丨姜长涛/乔杰/庞艳莉/郑明华/贾彦 ...· 3 天前 |

|
生信人 · 23年暴涨的热点思路,关注下吧· 4 天前 |

|
生信人 · 起底邵志敏科研版图,高分乳腺癌研究汇总· 6 天前 |
|
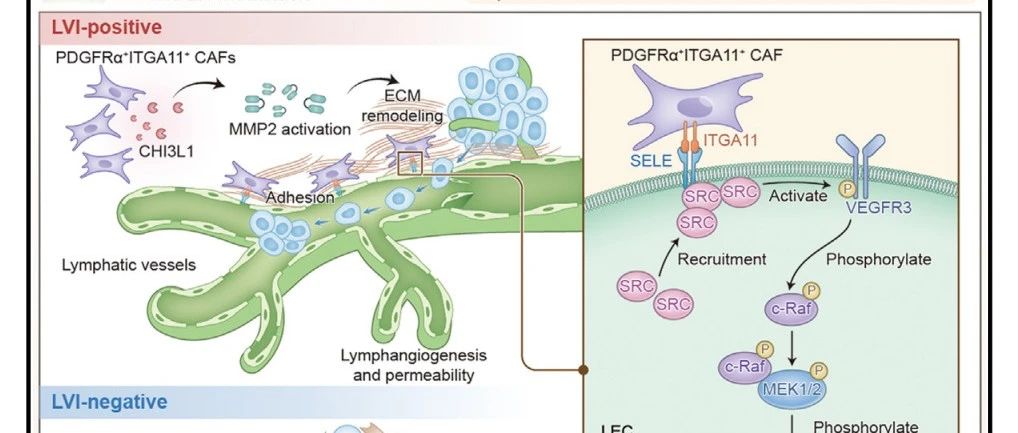
生信人 · 人手一篇的“淋巴转移”,摇身一变50+· 6 天前 |

推荐文章
|
|
生信人 · 23年暴涨的热点思路,关注下吧 4 天前 |
|
|
生信人 · 起底邵志敏科研版图,高分乳腺癌研究汇总 6 天前 |
|
|
生信人 · 人手一篇的“淋巴转移”,摇身一变50+ 6 天前 |

|
叔本华哲学智慧 · 季羡林:糊涂一点,潇洒一点 1 周前 |

|
远方青木 · 40年没打仗了,解放军还有战斗力么? 1 月前 |

|
新闻晨报 · 近期电动自行车火灾涉及这些品牌和电池,北京最新公布→ 1 月前 |

|
绿色和平行动派 · 工作机会|多个全职岗位开放招聘中 2 年前 |
