看啥推荐读物

专栏名称: 大数据与机器学习文摘
| 分享大数据技术相关文章和资源 |
今天看啥
微信公众号rss订阅, 微信rss, 稳定的RSS源
目录
相关文章推荐

|
数据派THU · 直播预告 | 多模态大模型的时代真的来了吗?· 3 天前 |

|
CDA数据分析师 · 数据治理企业应用实战课程——全流程拟真项目案例· 3 天前 |

|
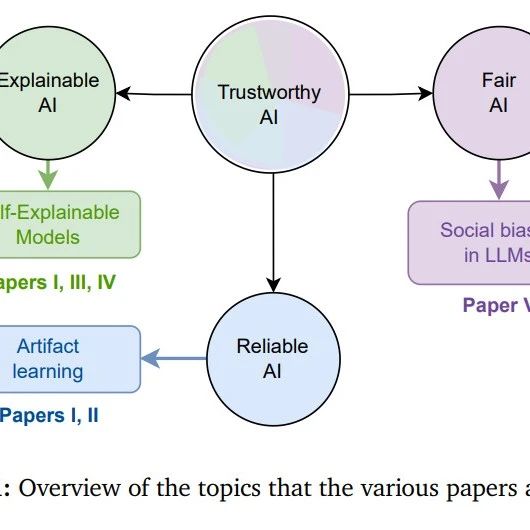
数据派THU · 【博士论文】可解释、可信赖和可靠的人工智能· 6 天前 |

|
InfoTech · 定了!正式通知:身份证1992-2005年出 ...· 4 天前 |

推荐文章
|
|
数据派THU · 直播预告 | 多模态大模型的时代真的来了吗? 3 天前 |
|
|
CDA数据分析师 · 数据治理企业应用实战课程——全流程拟真项目案例 3 天前 |
|
|
数据派THU · 【博士论文】可解释、可信赖和可靠的人工智能 6 天前 |



|
房屋快线 · 点此查看今日新房源2021.09.30 2 年前 |

|
第一地产 · 福布斯发布2018年最佳经商国家,第一名是它! 6 年前 |