看啥推荐读物

专栏名称: 数据派THU
| 本订阅号是“THU数据派”的姊妹账号,致力于传播大数据价值、培养数据思维。 |
今天看啥
微信公众号rss订阅, 微信rss, 稳定的RSS源
目录
相关文章推荐


|
大数据文摘 · 中国年轻人,不敢gap year· 3 天前 |

|
数据派THU · Moirai:Salesforce的时间序列 ...· 5 天前 |

|
艺恩数据 · 优酷精准把脉用户情绪,创新升级开拓综艺价值· 5 天前 |
|
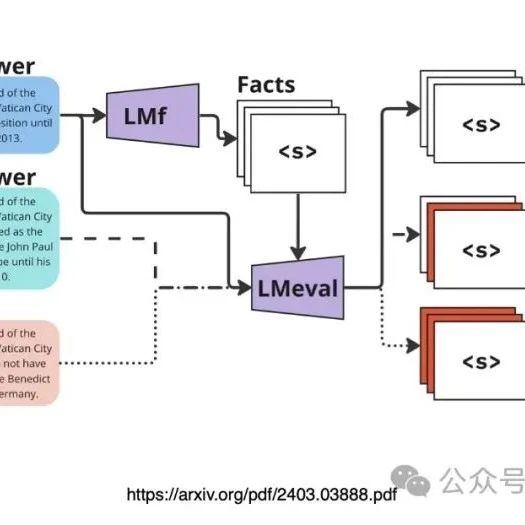
数据派THU · FaaF:为RAG系统量身定制的事实召回评估框架· 6 天前 |

推荐文章
|
|
大数据文摘 · 中国年轻人,不敢gap year 3 天前 |
|
|
艺恩数据 · 优酷精准把脉用户情绪,创新升级开拓综艺价值 5 天前 |
|
|
数据派THU · FaaF:为RAG系统量身定制的事实召回评估框架 6 天前 |

|
走出去直通车 · 风险预警 | 哥伦比亚 1 月前 |

|
史事挖掘机 · 武松真实死因终于揭开!不是六和寺病死,死法很惨烈 3 月前 |

|
E药研发 · 东阳光药业绩持续走高,预计上半年净利不低于10亿 4 年前 |

|
一起神回复 · 当代年轻人点外卖指南 4 年前 |

|
跟大厨学做菜 · 和老公睡完又和情夫......这女人一夜间火了 6 年前 |